
We use Cloudflare Workers extensively at Report URI and over the last few months we've been testing a major update to how we use them. With this recent change we've seen a monstrous drop in the volume of traffic we're handling at our origin. Here's how we did it.
Report URI and Cloudflare Workers
Prior to this change we were already using Cloudflare Worker to handle all of our inbound report traffic on Report URI, close to 10,000,000,000 reports per month on average. You can see the technical details of our existing use in my blog Utilising Cloudflare Workers to speed up Report URI and if you want some more detailed numbers there's Report URI: A week in numbers. The TLDR of both of those posts is that the Worker did things like basic validation on the JSON, a little filtering of bad reports and most importantly, if a user was over quota it wouldn't send the report to our origin because there'd be no point. This meant that of the 10,000,000,000 reports we'd be sent, the Worker would only make in the region of 1,400,000,000 subrequests to our origin, a very attractive 84% reduction in traffic! Still though, we could go further.
Buffering Reports
Just over a year ago I announced some other big changes to Report URI and the introduction of a Redis cache at our origin. This would allow us to buffer reports between us and Table Storage in Azure. Rather than inserting individual reports multiple times, we could buffer for a short period (10 seconds) and that would allow us to normalise and de-duplicate reports in that time period and do fewer inserts into Table Storage, reducing costs and improving performance. This worked amazingly well and I wondered if we could do the same thing with our Cloudflare Worker. Could the Worker somehow buffer inbound reports and dispatch them to our origin in batches instead of passing through every single report individually. After a little chat with Kenton Varda, the tech lead for Workers, it turns out that this wasn't so hard to do at all.
In essence, this worker will receive a request and start a batch if one does not exist. It will then wait for 10 seconds before processing this batch, during which time additional requests will continue to be placed into the batch. After 10 seconds the code to process the batch will be called and the process will start over. With this logic we could bundle together all of the JSON from inbound reports and dispatch it to our origin in a single request instead of potentially hundreds or thousands of requests given our inbound volume. To further improve on this we don't need to store duplicate reports, instead we store them in the object with a count, further reducing the size of the payload.
{
"{sha1(json)}": {"json": "{json}", "count": 123},
"{sha1(json)}": {"json": "{json}", "count": 234},
"{sha1(json)}": {"json": "{json}", "count": 345}
}Using the sha1() hash of the JSON payload as the key we then store an object that contains the actual JSON payload itself and a count. When a new report comes in we simpy check if the key exists and increment the count if it does, or insert a new object with a count of 1.
let buffer = new TextEncoder('utf-8').encode(JSON.stringify(json))
let hash = await crypto.subtle.digest('SHA-1', buffer)
let hashStr = hex(hash).toLowerCase()
if (typeof(batch[hashStr]) !== 'undefined') {
batch[hashStr].count += 1
} else {
batch[hashStr] = {'json': json, 'count': 1}
}Resource Limits
Buffering reports in the Worker like this will obviously consume more resources than each execution simply passing the request through to the origin. That said, we're not pushing the worker that hard and the resource limits set out by Cloudflare are pretty generous for our needs.

The per request time we're consuming is now tiny because the requests are being handled exclusively within the worker and simply creating or incrementing a count in a local variable. The next resource is memory and whilst yes we are creating and storing these reports in a local variable, for 10 seconds or less this does not result in any noteworthy memory usage. To put it plainly, we don't have anything to worry about in the resources department.
The Results
After extensive testing of this new Worker on my subdomain and those of some willing volunteers, we were ready to push the change out across the whole site. If everything went well then nobody would notice this change and the ony posible downside would be that reports may be delayed from getting into your account for a few extra seconds. The time came, we deployed, and nobody noticed a thing. Success!
The real test would come when we checked what changes we could see on our origin traffic, how much were we actually saving now? Here's our traffic graph for the last 30 days at the time of writing. As you can see, there's a pretty steady amount of traffic and no real changes to what's hitting us.
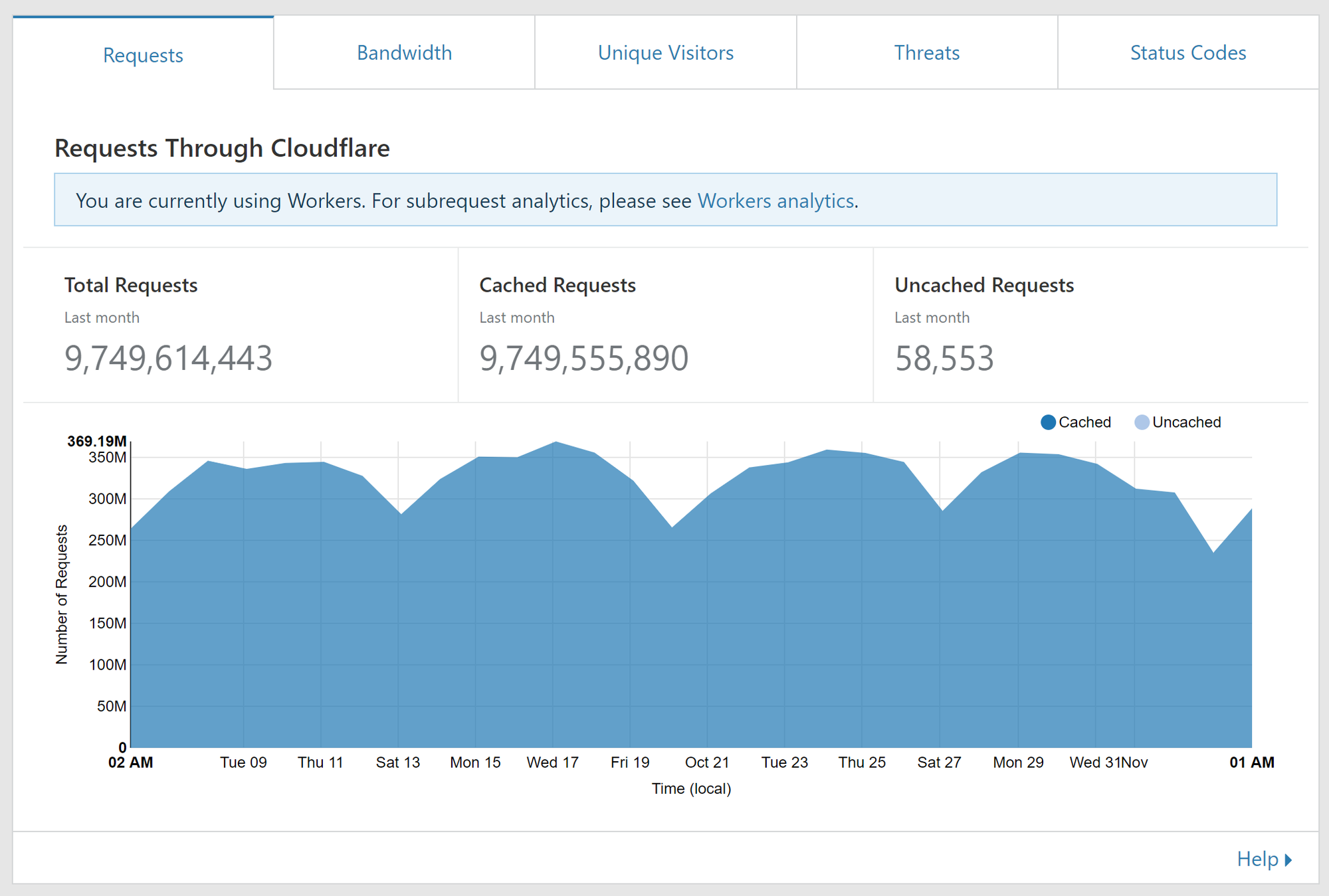
So that's the total number of requests that hit us and for clarity, we deployed the change on Oct 21. As you can see, no change in our normal volume. These requests are then fed into the Worker and the Worker may or may not make a request to our origin. You can also look at the amount of subrequests your Worker is making.
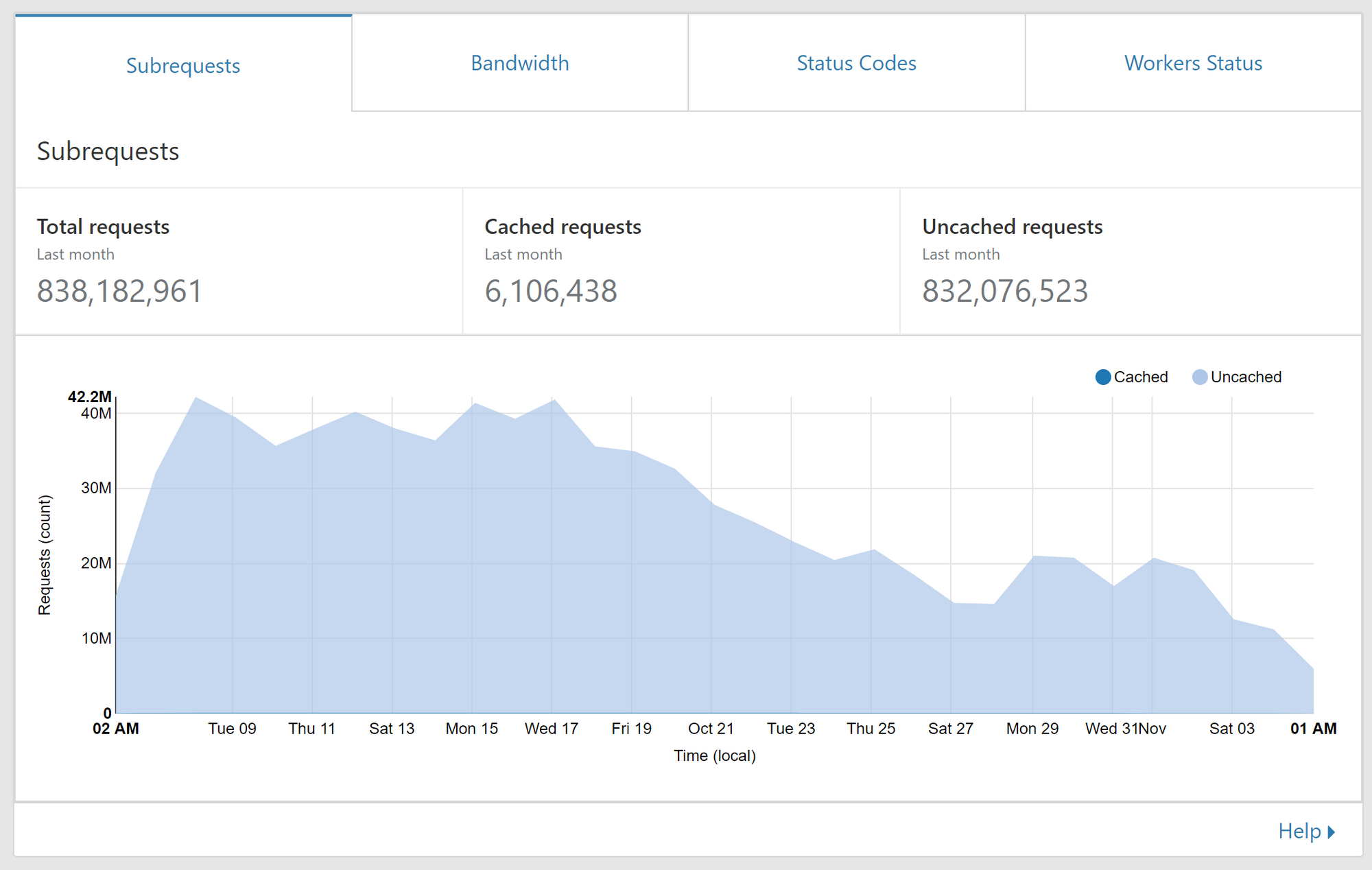
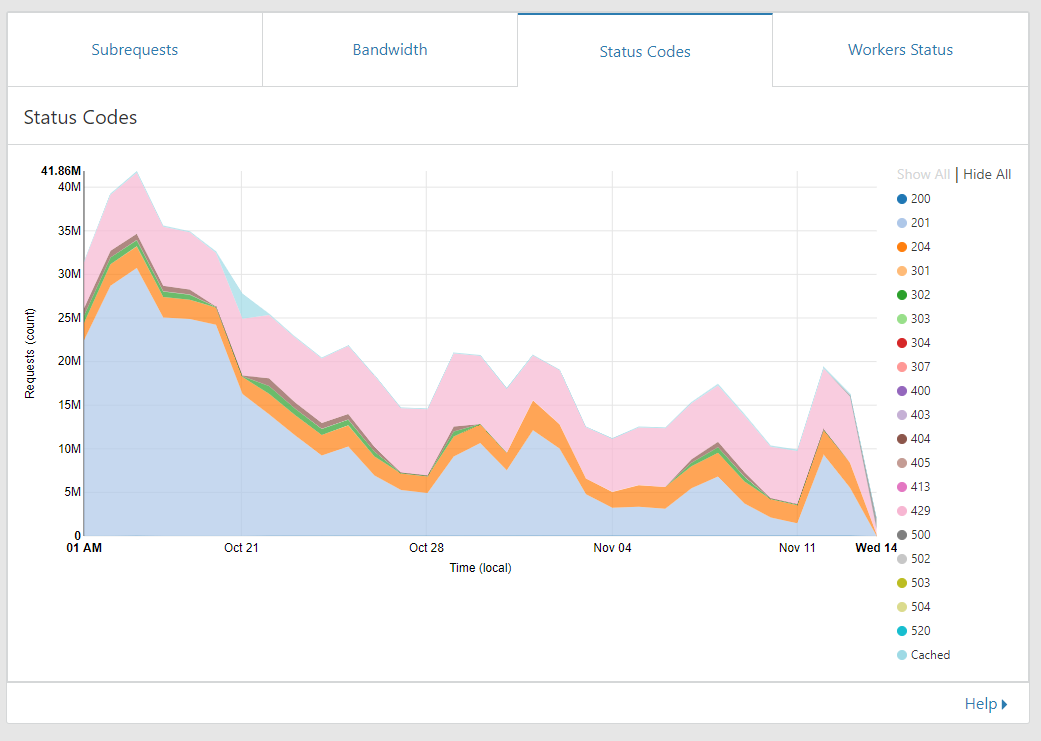
Now you can clearly see when we deployed the change on Oct 21! Looking at this graph there are 2 things that we should note. Prior to Oct 21 the number of subrequests from the Worker was significantly lower than the number of requests hitting the Worker. This is largely due to the worker filtering bad reports and dropping reports for users that were over their quota. That in itself was a significant reduction in traffic to our origin but the change on Oct 21 brought another significant reduction too. With the worker now buffering those requests each report that is sent to us doesn't result in a request to our origin. We opted for a more gentle start and currently the Worker is only buffering for 2 seconds before dispatching to our origin but that alone has given us a 50% reduction in requests made to our origin. As we start to gain confidence and test further we will increase the amount of time the Worker buffers for and should see further reductions in the number of subrequests made. You can also see the status codes from our origin back to the worker. The largest items are fairly clear and we have the pink section which is 429 responses, these are how our origin tells the worker that a user is over quota and should not accept reports. The worker caches this for a short period of time and applies it to all incoming reports. The next section is orange which is the 204 response. This is the worker asking for the status of a user and getting a response that they are not over quota, the same caching applies to these responses too. The largest section in blue at the bottom is the 201 responses from our origin which is the worker dispatching the groups of reports and our origin servers ackowledging receipt of them.
This change doesn't cost any more as the Worker is still being executed the same number of times and the cost is based on each execution but it should reduce the burden on our origin servers, and it did. Here's the CPU and network graphs for one of our ingestion servers which only handle inbound reports from the Worker.
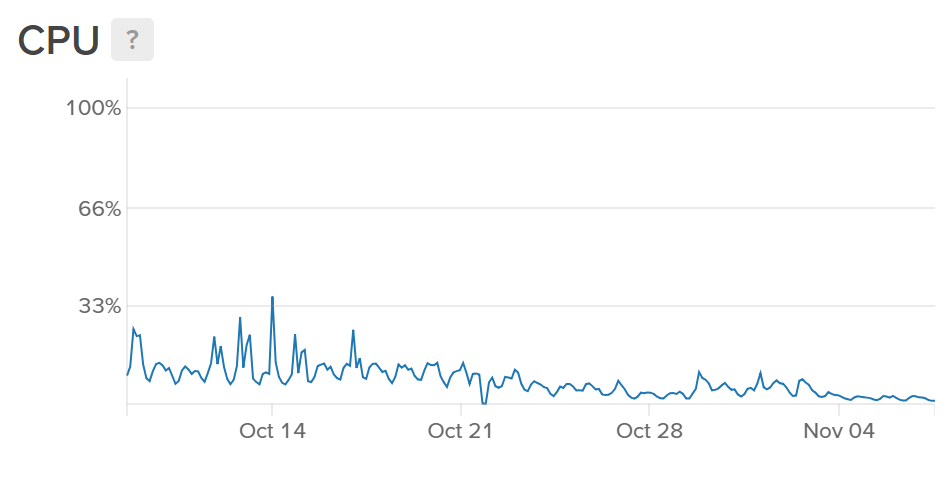
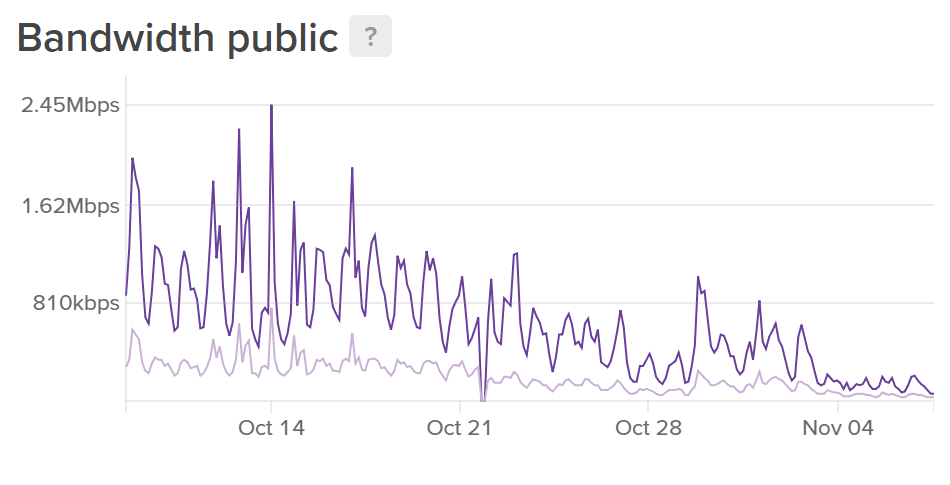
You can see from the graphs that there is a very apparent drop in resources from 21 Oct when we deployed the changes. The CPU is less busy as it's processing less inbound requests and the bandwidth is lower because the Worker is now de-duplicating reports and stacking them for us. Overall this is a pretty nice decrease in resource utilisation and as you can see we already run our servers with plenty of free capacity. This is largely due to the massive spikes we see in traffic when new users join and flood us with reports or more predictably on the 1st of the month when all of our users get their new quota and the Worker starts letting their reports through again. All of that said though, this change is enough to allow us to reduce the size of our fleet of servers and start to realise some cost savings from our use of Cloudflare Workers. Up until now we've been really reserved in dialing back our server resources but I think it's time we started!