
I've worked at some great companies during my career and worked alongside some great people too. Many of those I still keep in contact with and recently I spoke to an old colleague about joining him on a webinar to discuss bots, bot mitigation and the problems that bots pose.
We all think about bots
I have to admit that this is an area where I feel like I, along with many others, have thought about the problem but not really thought about the problem. I chuck around the word bots and talk about automated attacks, but it's a weirdly more interesting and complex topic than I'd realised.
A friend and old colleague of mine, James Maude, reached out and asked if I'd like to join him on a Webinar for the company he's now working at, Netacea. Knowing James, I knew there'd be technical and interesting topics at hand and that the often present 'eugh' feeling of pitchy webinars would not be top of the agenda. We bounced a few ideas around and I asked what kind of things they'd like from me but it was a quick decision that I'd join. I've done many webinars in the past and I've also been on many podcasts too, it's something I genuinely enjoy doing when the subject and the people are interesting!
In this blog I want to run through some of the things I talked about in the webinar, around topics like what we're doing for bot mitigation on high traffic sites like Report URI and Security Headers. As I mentioned, we do have things in place to deal with bots, but it's not anything that a particularly large amount of thought has ever gone into.
Bot Protection 101
One of the first things that many people, including myself, might think about when talking about bots, or more specifically stopping bots, is some kind of captcha. More specifically you're probably familiar with the Google version of this, reCAPTCHA. Indeed we do use reCAPTCHA on Report URI and you can see it here on our registration form.
We're using the v3 reCATPCHA which is the invisible one, meaning that no user input is required in order to complete the challenge, but you might be more familiar with the older version. In the v2 reCAPTCHA you had to click the checkbox to say "I'm not a robot" to complete the challenge and here's that box everyone is familiar with.
The reason that we have these seems quite obvious, we don't want someone/something spamming our registration form and filling our database with junk. That's quite easy to understand and, as a result, we have reCAPTCHA on our registration endpoint. Job done! No? One of the conversations I had with James went into far more detail around why someone might not want a registration form to be abused in this manner and there are quite a few good reasons. What if you use the number of signups as some form of indicator around the success of marketing campaigns or promotional activities? It could give you quite a misleading result if you think something is doing a lot better than it actually is. I'm sure like many other websites our registration process is labour intensive. We have to properly hash a password, there's database activity to create a new user, emails to send and other processes to kick off behind the scenes to get an account ready to use. Our registration endpoint is very 'expensive' and we don't want someone incurring a large workload by hammering it and perhaps even reaching DoS levels of harm. Maybe you have similar concerns somewhere on your application and endpoints that you feel need protecting, but we had another area on Report URI with a similar problem, report ingestion. When we take a JSON payload from the browser it's an unauthenticated POST request made to us from potentially anyone, anywhere in the world and it requires work. Sanitisation, schema validation, normalisation, filtering and eventually database activity to insert it and increment counts. The problem is there's no possible way to put a reCAPTCHA, or anything similar, in front of those reports...
IP Rate Limiting
The next logical step in the bot mitigation playbook is IP address rate limiting and this is another step that we take to protect our sites. When interacting with a website there is, somewhere, a reasonable level of traffic that you can expect to come from a user. They may forget their password and try to login once, twice or even three times, but a user trying to login 50 times per second? They're probably bad news!
There are countless ways to implement the technical feature itself, historically I used to use fail2ban, but these days you could well be better served by a CDN provider or native features of your server platform like nginx which has HTTP request rate limiting built in and I have also used that in the past too. I don't want to say that rate limiting like this is bad, because it's not, it's just not advanced enough to do the job all by itself.
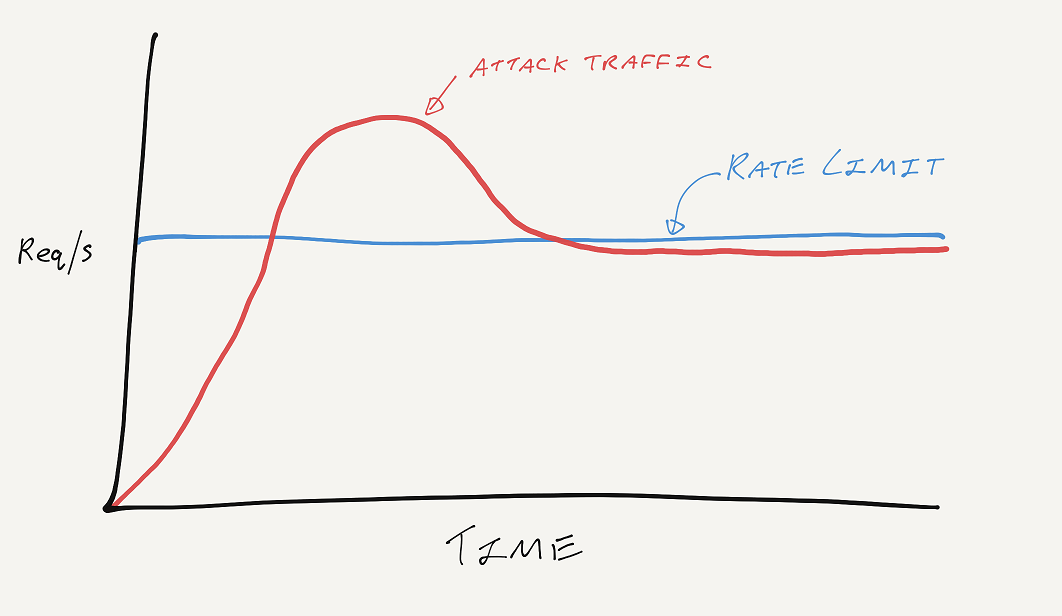
I've talked about abusive traffic patterns with Report URI here on my blog and on the public timeline on Twitter, and one thing that often happens is that an attacker will either just smash through the limit and have some of their traffic dropped, or, they will find the limit and sit just below it. Just like reCAPTCHA it's a good measure to have in place, but also just like reCAPTCHA, an attacker can work their way around it if they like by sending the attack from a large pool of IP addresses. Another trait that these two techniques have is that they are also pretty broad-brush approaches to the problem. These measures are applied against all visitors to the site equally, whether or not there is any suspicion of wrongdoing, and that's the part we're missing.
Getting smart about tackling the problem
The main reason that we don't put reCAPTCHA all over the place is that it would be super annoying to our users. The main reason that our rate limits are somewhat relaxed is that we don't want to risk limiting genuine traffic and being super annoying. There's a common thread here and it's one that many security professionals will be really familiar with: security often comes at the cost of user experience.
We can't just dial security up to 11 and expect our users to deal with the fallout. In our case at Report URI we want those users to become customers and I have a sneaky feeling that it's less likely to happen if they have a bad experience on our site. What we need to do is look at applying bot countermeasures only when they are appropriate, when we have some reasonable suspicion that the current activity is bot behaviour. If you are interested in that side of things then you should listen to the webinar right here and the things that we discussed. James had some examples of bots abusing business logic whilst using sites and whilst not necessarily doing anything wrong they are learning how to abuse legitimate functionality to achieve their goals. I don't want to go into them too much here as that's not the point of this blog and I'd just be duplicating what we discussed over on the recording anyway. What I do want to do though is pick up on some of the things that I found genuinely interesting as a result of participating.
What do bots want?
Apparently it can be almost anything! They could be price scraping on your e-commerce site, making reservations or bookings, testing credentials against your login to test if they're valid or testing credit cards on a payment flow to see if they're good. It turns out bots are a much more complicated game than I thought and that might just be because I've never been exposed to any of these specific threats. One thing that did surprise me was some of the more mundane (at least in my view) things that bots go after. Credential stuffing is a common problem across the web and something that Troy Hunt has talked a lot about. If you want to know the extent of these problems online he's a good person to follow and we've certainly had some interesting conversations on the topic! The TLDR is that someone takes a whole heap of username/email and password combinations, or a 'combo list', and runs them against a website to see if any of them work. Now, what kind of website? Well, I was thinking maybe PayPal or some other financial website, somewhere that the attacker could get access to money if they login. Perhaps an e-commerce site, they could login, change your delivery address and order a nice, new TV! But no, turns out some of the things these bots go after are far more... mundane. Things like Spotify accounts, it turns out, are a common target. I was in Australia earlier this year and I did some training and a talk at AusCert 2019. Whilst there I also got to watch Troy speak and he talked about exactly this problem. Here's the talk with a deep link to the appropriate part, check it out:
Now, I can't see the particular attraction of going after something like a Spotify account. There's no way to extract money, probably not an awful of lot useful/personal data in there and all you can really do is listen to music. But, it turns out, that's enough for someone to sell and make money off! These attackers are finding Spotify accounts that have spare family slots left and selling access to them. Want Spotify but with a really big discount? Great! We'll just add you on to someone else's account. It's not just Spotify accounts either, apparently a lot of online music/video streaming services are targets for exactly the same reason and another category that is targeted quite heavily is loyalty point schemes. You know when you go to the supermarket or buy petrol and you collect reward points? Yep, they're a target too because they're valuable and can be traded for money or used to buy valuable items if someone gets into your account.
Moving forwards
In many ways I'm lucky that Report URI and Security Headers don't suffer from the bot problem too much. We don't have loyalty points that can be traded for cash or an online service that can be shared to avoid subscription costs, but we do still have our own set of problems. Specifically on Report URI where we're taking those unauthenticated POST requests with JSON and processing them, we really don't want that open to abuse. Someone could submit false reports to our customers or simply overload us with data to process. Spotting bad behaviour on our report ingestion endpoints has been an important focus for us for quite a while and is something that we're always looking to improve. On that front, we will have something to announce in the coming months as we step up our game to not only protect ourselves, but to protect our customers too. Like any problem in security it's about taking steps forward. Some sites might be happy with no bot mitigation, some might be happy with a captcha and some might go to IP rate limiting, but there's a whole lot more you can depending on your own threat model. I don't know what's suitable for you, only you can make that determination, but for us, we need to take another step and up our game. As always, look forward to a post with technical details on what we did and how we did it!