
This is not a blog post that anybody ever wants to write, but we had some service issues yesterday and now the dust has settled, I wanted to provide an update on what happened. The good news is that the interruption was very minor in the end, and likely went unnoticed by most of our customers.

What happened?
I'm sure that many of you are already aware of the issues that Cloudflare experienced yesterday, and their post-mortem is now available on their blog. It's always tough to have service issues, but as expected Cloudflare handled it well and were transparent throughout. As a customer of Cloudflare that uses many of their services, the Cloudflare outage unfortunately had an impact on our service too. Because of the unique way that our service operates, our subsequent service issues did not have any impact on the websites or operations of our customers. What we do have to recognise, though, is that we may have missed some telemetry events for a short period of time.
Our infrastructure
Because all of the telemetry events sent to us have to pass through Cloudflare first, when Cloudflare were experiencing their service issues, it did prevent telemetry from reaching our servers. If we take a look at the bandwidth for one of our many telemetry ingestion servers, we can clearly see the impact.
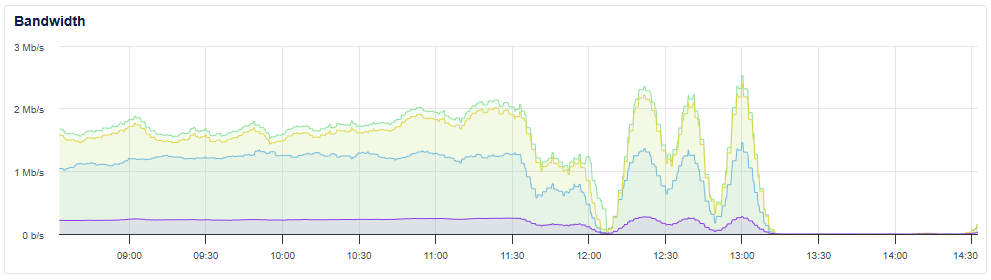
Looking at the graph from the Cloudflare blog showing their 500 error levels, we have a near perfect alignment with us not receiving telemetry during their peak error rates.
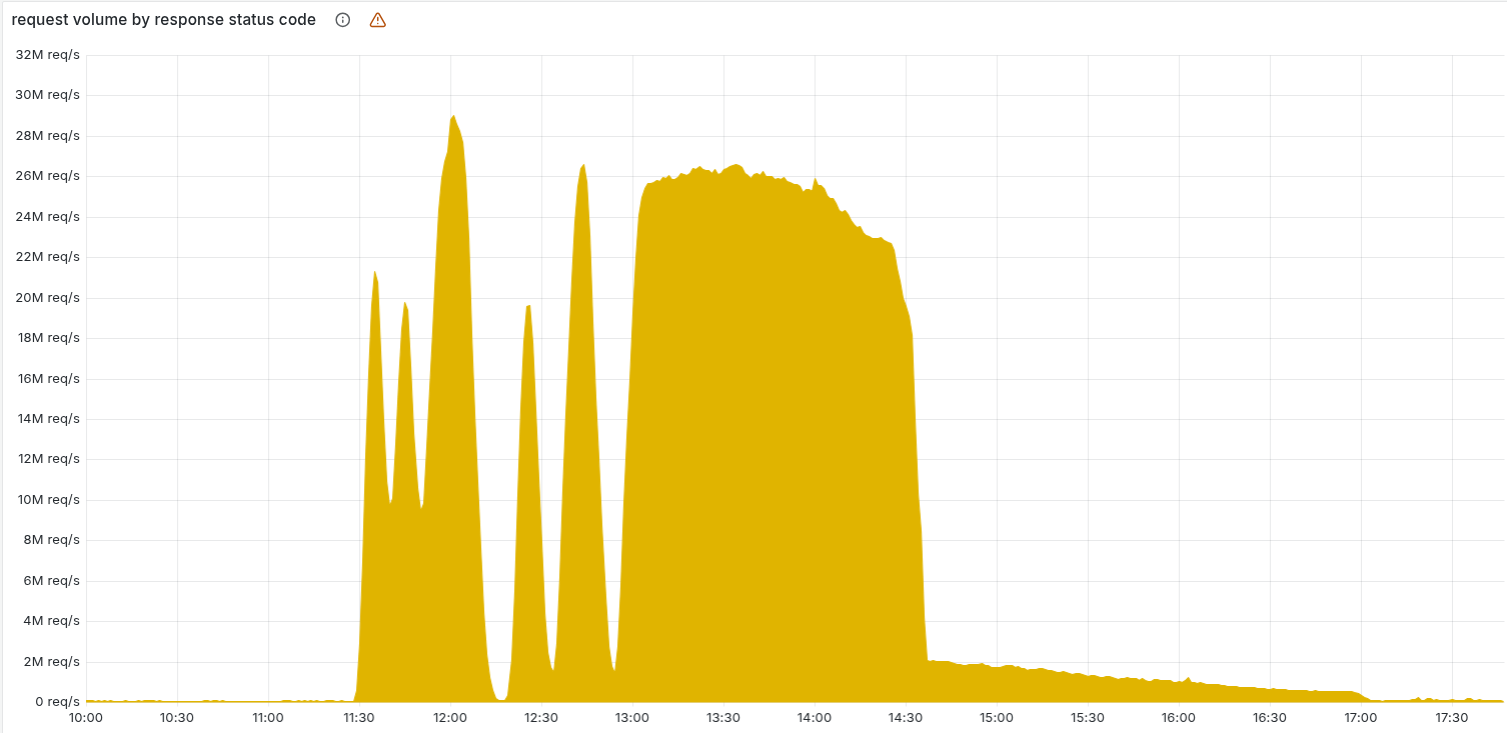
The good news here, as mentioned above, is that even if a browser can't reach our service and send the telemetry to us, it has no negative impact on our customer's websites, at all, as the browser will simply continue to load the page and try to send the telemetry again later. This is a truly unique scenario where we can have a near total service outage and it's unlikely that a single customer even noticed because we have no negative impact on their application.
The recovery
Cloudflare worked quickly to bring their service troubles under control and things started to return to normal for us around 14:30 UTC. We could see our ingestion servers start to receive telemetry again, and we started to receive much more than usual. Here's that same view for the server above.
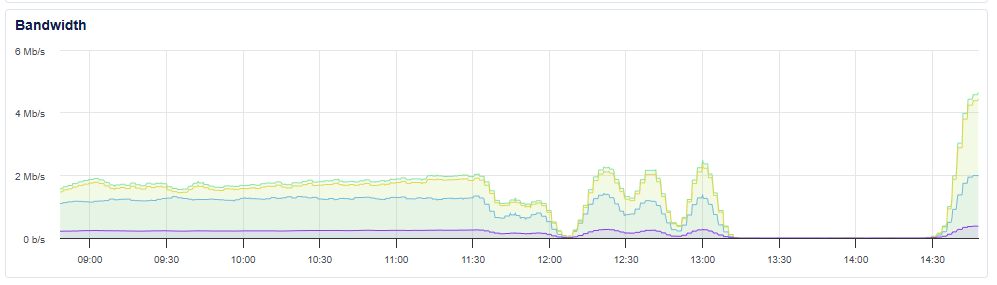
If we take a look at the aggregate inbound telemetry for our whole service, we were comfortably receiving twice our usual volume of telemetry data.
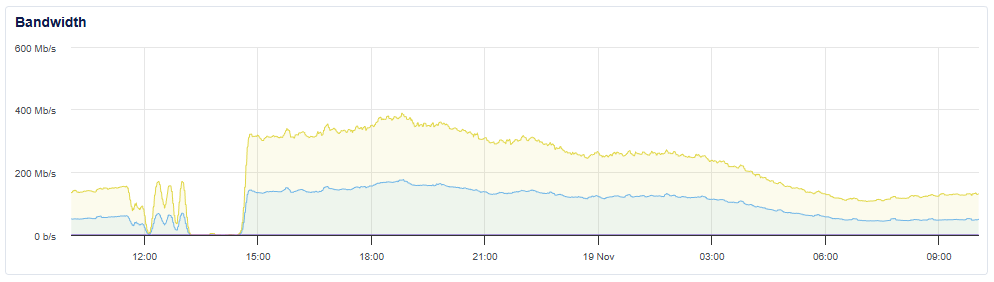
This is a good thing and shows that the browsers that had previously tried to dispatch telemetry to us and had failed were now retrying and succeeding. We did keep a close eye on the impact that this level of load was having, and we managed it well, with the load tailing off to our normal levels overnight. Whilst this recovery was really good to see, we have to acknowledge that there will inevitably be telemetry that was dropped during this time, and it's difficult to accurately gauge how much. If the telemetry event was retried successfully by the browser, or the problem also existed either before or after this outage, we will have still processed the event and taken any necessary action.
Looking forwards
I've always talked openly about our infrastructure at Report URI, even blogging in detail about the issues we've faced and the changes we've made as a result, much as I am doing here. We depend on several other service providers to build our service, including Cloudflare for CDN/WAF, DigitalOcean for VPS/compute and Microsoft Azure for storage, but sometimes even the big players will have their own problems, just like AWS did recently too.
Looking back on this incident now, whilst it was a difficult process for us to go through, I believe we're still making the best choices for Report URI and our customers. The likelihood of us being able to build our own service that rivals the benefits that Cloudflare provides is zero, and looking at other service providers to migrate to seems like a knee-jerk overreaction. I'm not looking for service providers that promise to never have issues, I'm looking for service providers that will respond quickly and transparently when they inevitably do have an issue, and Cloudflare have demonstrated that again. It's also this same desire for transparency and honesty that has driven me to write this blog post to inform you that it is likely we missed some of your telemetry events yesterday, and that we continue to consider how we can improve our service further going forwards.