
I recently wrote about a little hack we did with Azure Table Storage to give us functionality equivalent to a LIKE query in SQL, something not natively supported in Table Storage itself. This is another similar hack that I've used to give me the ability to order results based on a timestamp.
The first hack
First time around we needed to do LIKE queries that aren't supported by Table Storage so we came up with a nifty workaround: Hacking Azure Table Storage to do LIKE queries
Take a look at that post if you want to get an idea of how we did that but this post is going to focus on how we do ORDER BY, another operator not supported in Table Storage.
Entities, Properties and Indexes
Table Storage is a key:value store and entities (rows) have no fixed schema beyond the system required properties (columns). Those properties are the Partition Key and the Row Key and are used to create a clustered index for fast querying. This is the only index that exists and it's not possible to index on other fields so fast querying means clever use of the Partition Key and Row Key properties. I have a blog on the basics of working with Table Storage and how we optimise for performance too. At one point we were also using it as a fast, centralised session store for PHP. If you want to get up to speed on Table Storage those articles will make a good starting point but if you're already familiar, let's carry on.
Timestamp
The other required system property is the Timestamp and this isn't something set or managed by the user, the server will update this field each time an entity is modified. This would be great on a service like Security Headers where on the homepage we have a list of recent scans, we can just fetch the most recently modified entities in the results partition.
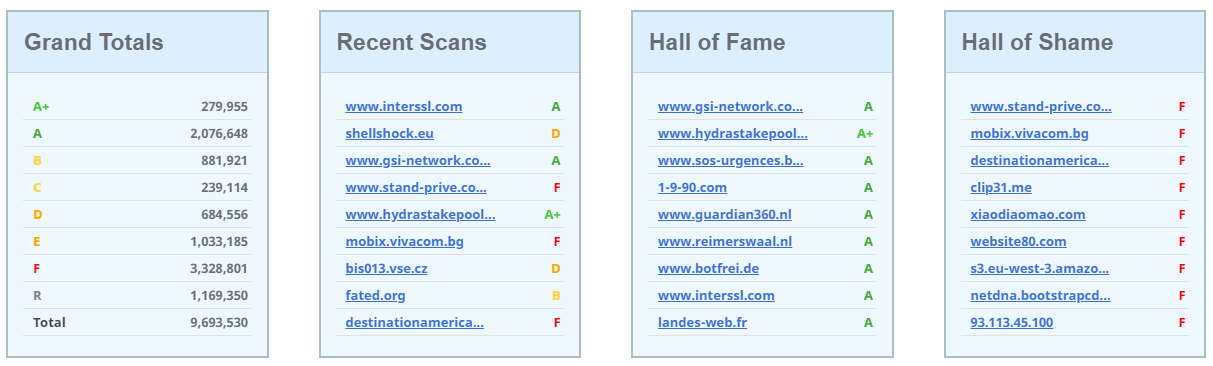
There are a few problems with this approach though and it's down to how we can query Table Storage. The filter string for a query like this would probably look something like the following.
"Timestamp ge datetime '" . Utilities::isoDate(new DateTime('-5 minutes')) . "'"
That filter will return all scan results where the Timestamp property indicates it has been created or modified within the last 5 minutes by using the greater than or equal ge comparison operator. It's a crude way to do it but assuming the level of traffic we get there is always going to be at least 9 entries returned here, enough to populate the tables on the homepage. The problem is this query could return a lot more than the 9 we need, up to 1,000 results, and they aren't in a useful order. By default the entities returned are sorted in alphanumeric order based on the Partition Key and Row Key concatenated together. There is a top operator where we can limit the number of results returned, but because of the ordering issue the 'top 9' might not be the 9 that we actually want. Time to get creative!
Re-purposing the Partition Key and Row Key
When using Table Storage you always want to be performing queries with the Partition Key and Row Key wherever possible, they're the fastest queries you can make. One of the other issues with the query above was that it didn't use an indexed property so it'd result in a full table scan for the query, or at best a full partition scan if we provided a Partition Key, but either way, it was going to be a slow query. I want fast querying so the Partition Key and Row Key needed to be used in an ideal scenario. Sorting out the Partition Keys was easy enough.
PartitionKey: recentScans
PartitionKey: recentGood
PartitionKey: recentBad
Those are the partition keys I went for in the end and they're pretty clear on what they do and allow me to to narrow down the data that needs querying over from a full table scan to just a partition scan, but we still need to go faster. The next problem was how to include the Row Key in a useful way. Logic dictated that the timestamp had to go in the Row Key and at first glance that sounds like a great solution.
RowKey: time()
By using time() I could now have a time based value in the Row Key that I could query against, meaning fast queries! That might take the following form.
"PartitionKey eq 'recentScans' and RowKey ge '" . time() - 300 . "'"
Narrowing it down with a Partition Key is good and the Row Key gives us an indexed field to search on which is even better, but this query still has a limitation. Because of the alphanumeric sort on the combination of Partition Key and Row Key the table storage service will start returning entities that match this criteria and I actually only want the last 9 it returns. This means I still can't use top and if the query returns more than 1,000 entities I have to call back and start paging with the continuation tokens. This is less than ideal. I could reduce the time window I'm querying for to try and reduce the entities returned but make sure I always have at least the 9 I need but that was just messy and prone to fail at some point. The issue was the alphanumeric sorting, I needed to reverse it, but how?
Set a self destruct date
If the number of seconds was counting down, and not up, then the problem of the alphanumeric sorting wouldn't be a problem, it'd become a feature. I could then use the top query and just grab the top 9 entities from the partition, problem solved. To do that I had to subtract the current time() value from another larger, much larger, value so that it was always reducing. The value I chose was 2,000,000,000 which is 18th May 2033 03:33:20 UTC as a unix timestamp. The date isn't special, I just liked the round number!
RowKey: str_pad(strval(2000000000 - time()), 10, "0", STR_PAD_LEFT)
The new Row Key is now a decreasing timestamp counting towards the inevitable and complete destruction of Security Headers as a service. On the bright side the alphanumeric sorting is now perfect for our needs and means we can do a top query instead.
$options = new QueryEntitiesOptions();
$filter = "PartitionKey eq 'recentSeen'";
$options->setFilter(Filter::applyQueryString($filter));
$options->setTop('9');
This filter now queries over exactly 9 entities and it's exactly the 9 entities we want returning. The downside is we now have a self destruct timer ticking, but let's not dwell...
Log data in Table Storage
If you want to use Table Storage for any kind of log data then making sure you utilise the Partition Key and Row Key properly will be really important. Even if you don't want or need to invert the time value like I've done above, using the Row Key in the standard incrementing fashion will allow you to do fast range queries on an indexed property.
"PartitionKey eq 'logs' and RowKey ge '" . strtotime('-2 weeks') . "' and RowKey le '" . strtotime('-1 week') . "'"
That will give you all log entries between the current date 2 weeks ago up to 1 week ago and is flexible for any range you need to query. Also, if time() isn't granular enough, you can switch to microtime() instead and gain even further granularity by appending random bytes to the end of the Row Key and padding to a fixed length. I can quite comfortably insert several thousand rows per second into Table Storage using this method and of course, you can increase that even further by splitting across partitions!